Research process: Coding
2019-07-04
The first time I learned about “coding” in social science research, the term vaguely bothered me. I couldn’t see a clear analogy between the meaning I was used to—expressing ideas and logic in some kind of formal system—and this other meaning, which has more to do with drawing ideas out of observations to construct an interpretation. But the notion of representing and interpreting meaning as “code” is so fundamental that it can’t really belong to just one science or knowledge community. Anyway, I’ve been doing a lot of coding lately.
In qualitative data analysis, coding means associating pieces of data with analytical concepts or categories. Those concepts can be derived from theory, or through an inductive process from the observations themselves. By doing this, researchers can create a fine-grained map of where different kinds of meaning might be revealed in a dataset. They can use that map to take further analytical steps: retrieving subsets of data, identifying patterns and connections, even doing some statistics.
Here’s an example of what this looks like in my own research process.
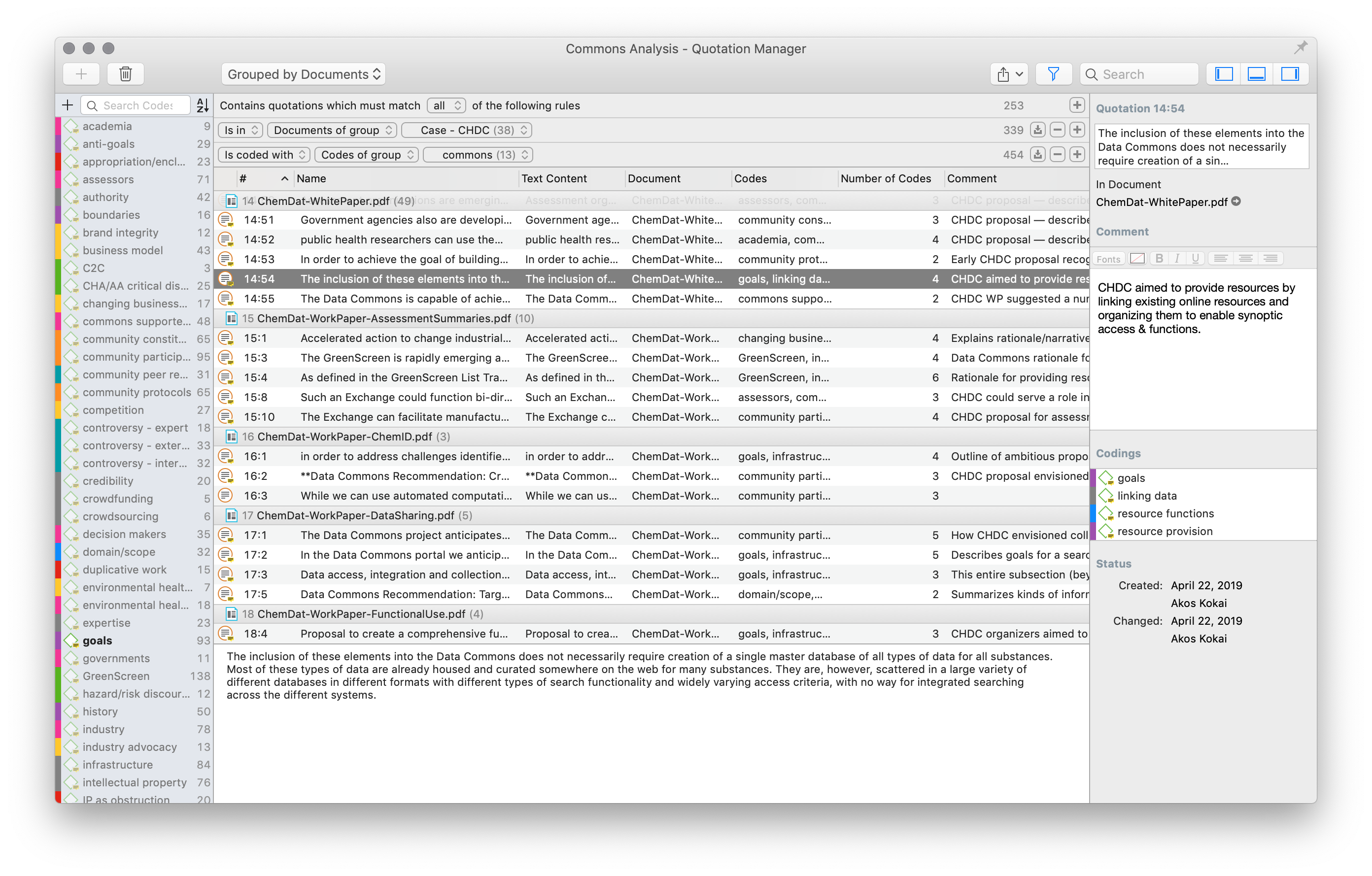
In this screenshot I’m using ATLAS.ti to retrieve all the fragments of my collected documents and interview transcripts that have to do with a certain case study, and that are associated with codes from a certain conceptual group that I created. Each fragment is something that I looked at and thought, “this is about linked data” or “this says something about who participates in commons.”
One thing I appreciate about qualitative coding is that I’ve had to pay careful attention to each data point in the process. It’s definitely not big data—but it’s important data, at least for my project.
Sometimes I think this should be called “decoding”—in those moments when it seems like the meaning is already there in the data.
A quick look at Wikipedia’s disambiguation page reveals a broad and interesting list of other things that people call coding. This research technique is among them. It’s how we order and crystallize meaning out of the fragments of reality that we observe with great difficulty and artifice.